1. 데이터베이스
특정 조직의 업무 수행에 필요한 상호 관련 데이터들의 집합
1.1 데이터베이스의 목적
- 파일 시스템의 문제
- 플랫폼이 바뀌면 사용할 수 없다.
- 데이터의 일관성, 보안성, 경제성, 무결성 면에서의 관리가 어려움
- 데이터의 일관성, 무결성 유지
- 데이터 검색, 수정, 삭제 용이
1.2 데이터 베이스의 정의
통합된 데이터 (integrated data)
- 데이터베이스에 원칙적으로 똑같은 데이터 중복 X
- 데이터 중복은 관리상 문제를 초래할 가능성이 높음
- 실제로는 완전히 중복을 배제하는 것이 아니라 효율성을 위해 불가피하게 일부 중복을 허용하기도 함
저장된 데이터 (stored data)
- 컴퓨터가 접근할 수 있는 매체에 저장된 데이터
- 주로 하드디스크에 저장되어 관리
운영 데이터 (operational data)
- 존재 목적이 명확함
- 어떤 조직의 고유 기능을 수행하기 위해 반드시 유지되어야 하는 데이터
- 일시적으로 필요한 임시 데이터 X
공용 데이터 (shared data)
- 여러 사용자가 서로 다른 목적으로 공유 가능한 데이터
- 여러 시스템이 공동으로 소유하고 유지하는 데이터
1.3 데이터베이스의 특징
실시간 접근성 (real-time accessibility)
- 수시적으로 비정형적인 사용자 요구(질의)에 대해 실시간으로 응답이 가능해야 함
지속적인 변화 (continuouse evolution)
- 동적인 데이터베이스 상태를 항상 최신으로 유지해야 함
- 새로운 데이터 삽입, 삭제, 갱신으로 변화된 데이터의 최신 사애를 그대로 반영하여 저장
동시 공유 (Concurrent sharing)
- 동일 데이터를 동시에 서로 다른 목적으로 사용할 수 있어야 함
내용에 의한 참조 (Content Reference)
- 데이터 위치 또는 주소가 아닌 값에 의한 참조
- 주소에 다른 값이 저장되어 있는 경우 원하는 값을 찾을 수 없는 문제 발생
- 내용에 의한 참조는 시간이 조금 더 걸릴 수 있으나 정확한 데이터를 찾을 수 있음
1.4 데이터베이스 관련 용어

식별자 (identifier)
- 여러개의 집합체를 담고 있는 데이터베이스에서 각 데이터브를 구분할 수 있게 하는 논리적 개념
- 특성
- 유일성 : 하나의 릴레이션 (테이블) 에서 모든 행은 서로 다른 키를 가져야 함
- 최소성 : 꼭 필요한 최소한의 속성으로 키를 구성해야 함
튜플 (Tuple)
- 테이블 행 (Row)
- 레코드 (Record)
- 서로 같은 값을 가질 수 없음
- 튜플의 수 = cardinality
속성 (Attribute)
- 테이블 열 (Column)
- 속성의 수 = degree
1.5 데이터베이스 계층 구조
- 컴퓨터가 기억하는 가장 작은 단위 bit
- 8 bit = 1 byte
- 바이트가 모여 숫자 또는 문자 등의 특정한 종류 데이터
- 데이터를 저장하기 위한 영역 필드 (field)
- 필드가 모여 레코드 (record)
- 레코드가 모여 파일 (file)
- 관계가 있는 파일들이 논리적으로 연결되어 필요한 부분을 적절히 찾고 활용할 수 있도록 한 것이 데이터베이스 (database)
1.6 데이터 모델링
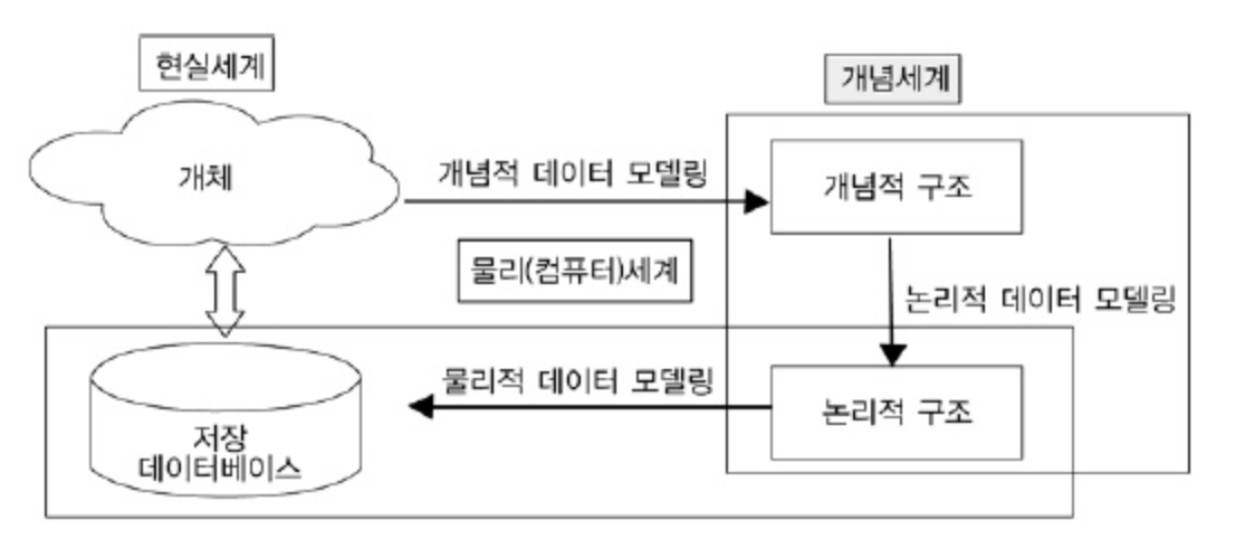
개념적 데이터 모델링
- 핵심 엔티티, 엔티티간 관계, 속성을 발견하는 모델링
- ERD 생성
- 사용자와 시스템 개발자가 데이터 요구사항을 발견할 수 있도록 기능
논리적 데이터 모델링
- ERD를 기반으로 릴레이션, 키, 속성, 관계를 정확히 표현하는 핵심 모델링 단계
- 식별자 확정, 정규화, M:M 관계 해소, 참조 무결성 규칙 정의 등
물리적 데이터 모델링
- 실제 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적 성격을 고려하여 설계하는 단계
- 테이블, 컬럼 등 표현되는 물리적 저장 구조 및 저장장치, 자료 검색시 사용될 접근 방식 등을 결정
1.7 스키마 (Schema)
스키마 정의
- 데이터베이스의 구조와 제약 조건에 관한 전반적인 명세를 기술한 메타데이터 집합
- 데이터베이스를 구성하는 데이터 개체 (entity), 속성 (attribute), 관계 (relationship) 및 데이터 조작 시 데이터 값들이 갖는 제약 조건
계층적 스키마

외부적 스키마에 따라 명시된 사용자의 요구를 개념적 스키마에 적합한 형태로 변경하고 이를 다시 내부적 스키마에 적합한 형태로 변환
- 외부 스키마 (External schema)
- 사용자 관점의 데이터베이스 논리적 구조
- subschema
- 하나의 DBMS에 여러 외부 스티마가 존재할 수 있으며, 하나의 외부 스키마를 여러 DBMS가 사용할 수 있음
- SQL로 DB에 접근 가능
- 개념 스키마 (Conceptual Schema)
- 기관 및 조직체의 관점의 데이터베이스 전체적인 논리적 구조
- 모든 데이터를 종합한 조직 전체의 DB로 하나만 존재
- 개체간 관계, 제약 조건, 접근 권한, 보안 및 무결성 규칙에 관한 명세 정의
- 데이터베이스 파일에 저장되는 데이터의 형태
- 단순히 스키마라고 할 경우, 개념 스키마를 말하는 것
- DBA 데이터베이스 관리자에 의해 구성
- 내부 스키마 (Internal Schema) / 저장 스키마 (Storage Schema)
- 시스템 프로그래머나 시스템 설계자 관점
- 물리적 저장장치 관점의 데이터베이스 구조
- 실제로 데이터베이스에 저장될 레코드의 물리적 구조, 데이터 항목 표현 방식, 물리적 순서 등을 정의
2. ERD (Entity Relationship Diagram)
개체 속성과 개체 간 관계를 표현한 다이어그램 데이터 모델링 단계에서 작성
- MySQL workbench 사용
2.1 ERD 구성 요소
개체 Entity

- 관리하고자 하는 대상 / 현실 세계의 객체
- 이름 단수형, 유일, 개문자
- 하나 이상의 식별자 가져야 함 (UID / Unique Identifier)
- # : UID
속성 Attribute
- entity를 구성하고 있는 요소
- entity와 이름이 같으면 안됨
- * : 필수 속성 (mandatory)
- o : 선택 속성 (optional)
관계 Relationship

- entity 간의 관계
- 선택 사항 표시
- 식별 (실선) : 필수
- 비식별 (점선) : 선택
- 관계 형태 표시
- | : 하나
- ∈ : 여러개
- ○ : 선택
2.2 ERD 관계 형태
1:1 관계
- 잘 발생되지 않는 형태
- 양방향 모두 반드시 단 하나씩 존재해야 함
- ————— - - - - - -
M:1 관계
- 한쪽 방향에는 하나 이상, 다른쪽은 단 하나만 존재
- 가장 일반적인 형태
M:M 관계
- 양방향 모두 하나 이상씩 존재
- 자주 발생하는 형태지만 최종 결과에서는 드물게 발생 → 개념 모델링 과정에서 M:1로 분할하기 때문에
2.3 ERD 표현법
관계선 종류
- 실선
- 식별 관계
- 부모테이블의 기본키가 자식테이블의 외래키 또는 기본키인 경우
- 부모가 있어야 자식이 있는 경우
- 즉, 자식 테이블은 부모 테이블 없이 존재하지 않음
- 점선
- 비식별 관계
- 부모테이블의 기본키가 자식 테이블의 일반 속성인 경우
- 자식이 부모와 독립적으로 존재할 수 있는 경우
기호의 종류 (식별자)
- |: 1개 / 실선은(dash) ‘1'을 나타낸다.
- ∈: 여러개 / 까마귀 발(crow’s foot or Many)은 ‘다수' 혹은 '그 이상'을 나타낸다.
- ○: 0개 / 고리(ring or Optional)은 ‘0'을 나타낸다.
기호 + 관계선 조합 의미

- A는 항상 하나가 있음을 가정
- Type1 : A와 B가 정확히 하나씩 존재함
- Type2 : 여러개의 B가 존재함
- Type3 : B가 반드시 1개 이상 존재함 (B가 없을 수 없음)
- Type4 : B가 0개 아니면 하나 존재 (없거나 1개 있거나 / 여러개일 수 없음)
- Type5 : B가 0개 또는 하나 이상 (없어도 되고, 있어도 되고, 여러개여도 됨)
3.DBMS (DataBase Management System)
데이터를 편리하게 저장하고 효율적으로 관리할 수 있는 환경을 제공하는 시스템 소프트웨어
3.1 DBMS의 구성 요소
- 데이터베이스
- 스키마
- 데이터베이스 언어
- 데이터베이스 컴퓨터
- 데이터베이스 사용자
- 데이터 사전 (Data Dictionary : DD) : RDBMS에서 객체를 정의하게 되면 그 객체가 가진 메타데이터 정보가 저장되는 곳으로 사용자는 접근할 수 없고 오직 시스템에서만 사용 가능
3.2 RDBMS (Relational DataBase Management System)
관계형 데이터베이스 관리 시스템 가장 일반적인 형태의 DBMS 테이블 구조
- 오라클, 사이베이스, 인포믹스, MySQL, Access, SQL server
장점
- 작성과 이용이 비교적 쉬움
- 확장 용이
- 처음 데이터베이스 생성 이후 관련 응용 프로그램을 변경하지 않고도 새로운 데이터 항목 추가 가능
3.3 SQL (Structured Query Language)
사용자와 관계형 데이터베이스를 연결시켜주는 표준 검색 언어
- 데이터베이스에 저장된 데이터를 조회, 입력, 수정, 삭제 등의 조작
- 테이블, 객체 등을 생성 및 제어
- 비절차적 언어로 형식은 존재하지만 명령어간 순서 없음
3.3.1 데이터 정의어 (DDL / Data Definition Language)
- 데이터베이스 논리적 구조 정의를 위한 언어
- 데이터사전에 저장됨
- 스키마, 도메인, 테이블, 뷰, 인덱스 정의, 변경, 삭제
- CREATE : 데이터베이스/테이블 생성, 정의
CREATE DATABASE [database name] CHARACTER SET [character set];
CREATE TABLE [table name] ([column1 name][data type], ...);
ex)
CREATE TABLE User(
ID INT,
NAme VARCHAR(30),
Birthday DATE,
Age INT
);- USE : 데이터베이스 선택
USE [database name];- ALTER : 테이블 변경 (테이블 필드/열 조작)
- 추가
- ALTER TABLE [table name] ADD [column name][datatype];
- 변경
- ALTER TABLE [table name] MODIFY COLUMN [column name][datatype];
- 삭제
- ALTER TABLE [table name] DROP [column name];
- 추가
- DROP : 데이터베이스/테이블 삭제
DROP DATABASE [database name];
DROP TABLE [table name];- RENAME : 테이블 객체 이름 변경
- TRUNCATE : 테이블 저장 공간 삭제 (DROP 후 CREATE)
3.3.2 데이터 조작어 (DML / Data Manipulation Language)
- 사용자가 데이터 처리할 수 있게 하는 도구
- 사용자와 DBMS 간 인터페이스 제공
- 사용자가 DB 데이터를 실질적으로 조작할 수 있도록 하기 위해 다양한 언어에 DB 기능을 추가해서 만든 언어
- 테이블 레코드 (행) 조작
- SELECT : 데이터 조회
SELECT * FROM [table];- INSERT : 데이터 추가
INSERT INTO [table name] VALUES (value1, value2, value3…);
ex)
INSERT INTO User(ID, Name, BirthDay) VALUES(1, '김태하', '1992-11-04');- UPDATE : 데이터 갱신
UPDATE [table] SET [column]=[value] WHERE [condition];
ex)
UPDATE User SET Age = 30 WHERE Name = '김태하';- DELETE : 데이터 삭제
DELETE FROM [table] WHERE [condition];3.3.3 데이터 제어어 (DCL / Data Control Language)
- 데이터 무결성, 보안 및 권한 제어 회복 등을 위한 언어
- 시스템 장애를 대비한 회복 및 병행 수행 제어
- 데이터 정확성을 위한 무결성 유지
- 불법적인 사용자로부터 데이터 보호를 위한 데이터 보안
- GRANT : 사용자에게 권한 부여
GRANT [권한 종류] ON [대상] TO [user id]@[host] IDENTIFIED BY [password] ([WITH GRANT OPTION]);
// 계정 생성 후, 변경된 내용 적용을 위해 실행
FLUSH privilieges;
SHOW GRANTS FOR [user id]@[host]- REVOKE : 사용자 권한 취소
REVOKE [권한 종류] ON [대상] FROM [user_id]@[host]- 권한 종류
- CREATE, ALTER, DROP, SELECT, INSERT, UPDATE, DELETE (=일반 사용자)
- RELOAD : 권한 부여된 내용 리로드
- SHUTDOWN : 서버 종료 작업 실행
- ALL : 모든 권한 허용 (=관리자와 동급)
- USAGE : 권한 없이 계정만 생성
- 대상
- * : 서버의 모든 데이터베이스, 테이블에 대한 접근 허용
- 데이터베이스명.* : 특정 데이터베이스의 모든 내용에 대한 접근 허용
- 테이터베이스명.테이블명 : 특정 데이터베이스의 특정 테이블에 대한 접근 허용
- 사용자 계정 명
- MySQL 서버 접속시 지정하는 이름
- 계정명과 호스트로 구성
- 암호
- IDENTIFIED BY 없으면 암호 없는 계정 생성
3.3.4 트랜젝션 제어어 (TCL / Transaction Control Language)
- COMMIT : 트랜잭션 작업 결과 반영
COMMIT;- ROLLBACK : 트랜잭션 작업 취소 및 원상복구
- 하나의 트랜잭션 처리가 비정상적으로 종료되어 데이터베이스 일관성이 깨진 경우 모든 변경 작업 취소하고 원상 복구하는 연산
- 트랜잭션 시 받았던 자원과 락 모두 반환하고 재시작 또는 폐기
- 마지막 commit 이후 작업으로 돌아감
- commit 없다면 모든 작업 사라짐
ROLLBACK TO [savepoint name];- SAVEPOINT : 저장 지점 설정
- 현재 트랜잭션을 작게 분할하는 명령어
- savepoint까지 rollback 가능
- savepoint 후 commit 연산을 하게 되면 commit 연산 이전에 만든 savepoint들 모두 사라짐
SAVEPOINT [pointer name];
- LOCK : 트랜잭션이 수행되는 동안 특정 데이터에 대해 다른 트랜잭션이 동시 접근하지 못하도록 제한하는 기법
3.4 KEY
데이터베이스에서 조건을 만족하는 튜플(row)을 찾거나 순서대로 정렬할 때 튜플들을 서로 구분하는 기준이 되는 속성(column)
후보키 (Candidate key)
- 테이블을 구성하는 속성 중 튜플을 유일하게 식별할 수 있는 속성의 부분집합
- 기본 키로 사용할 수 있는 속성들
- 하나의 릴레이션에 반드시 하나 이상의 후보키 존재해야 함
- 모든 튜플에 대해 유일성, 최소성 만족
기본키 (Primary key)
- 후보키 중 선택한 키 (main key)
- 릴레이션 내에서 특정 튜플을 유일하게 구별할 수 있는 속성
- null 값을 가질 수 없음
- 유일성, 최소성 만족
대체키 (Alternate key)
- 후보키가 둘 이상일 경우 기본키를 제외한 나머지 후보키
- = 보조키
- 후보키 - 기본키 = 대체키
슈퍼키 (Super key)
- 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키
- 유일성 만족
- 최소성 만족 X
외래키 (Foreign key)
- 관계를 맺고 있는 릴레이션 R1, R2에서 R1이 참조하고 있는 R2의 기본키와 같은 R1의 속성
- R2의 기본키 = R1의 외래키
- 참조 관계를 표현하는 키
3.5 Join
둘 이상의 테이블을 연결해서 데이터를 검색하는 방법

- 연결하려는 테이블 간 적어도 하나의 속성을 공유하고 있어야 함
- 공유하는 속성 = 기본키 또는 외래키
INNER JOIN
- 교집합
- 테이블의 공통 부분만 SELECT
SELECT [select_list]
FROM [table1 name]
INNER JOIN [table2 name]
ON table1.key = table2.keyLEFT/RIGHT JOIN
- join 기준 왼쪽/오른쪽 테이블에 있는 것 전부 조회
SELECT [select_list]
FROM [table1 name]
LEFT/RIGHT JOIN [table2 name]
ON table1.key = table2.key- join 기준 왼쪽/오른쪽 테이블에 있는 것만 조회 (공통 부분 제외) (= outer join)
SELECT [select_list]
FROM [table1 name]
LEFT/RIGHT JOIN [table2 name]
ON table1.key = table2.key
WHERE table2.key IS NULLFULL OUTER JOIN
- MySQL에는 없음
- join한 두 테이블에서 공통 부분을 제외한 것들 조회
SELECT [select_list]
FROM [table1 name]
LEFT JOIN [table2 name]
ON table1.key = table2.key
UNION ALL
SELECT [select_list]
FROM [table1 name]
RIGHT JOIN [table2 name]
ON table1.key = table2.key
WHERE table1.key IS NULLReferences
- https://halfmoon9.tistory.com/26
- https://m.blog.naver.com/PostView.nhn?blogId=salagswk&logNo=150045673259&proxyReferer=https:%2F%2Fwww.google.com%2F
- https://coding-factory.tistory.com
- https://velog.io/@taeha7b/mysql-in-a-nutshell
- https://extbrain.tistory.com/44
- https://kkamikoon.tistory.com/171
- https://bamdule.tistory.com/46
- https://eyecandyzero.tistory.com/246
- https://www.bsidesoft.com/4754
- https://doorbw.tistory.com/229
'컴퓨터 공학 > 데이터베이스' 카테고리의 다른 글
| 정규화 Normalization (0) | 2022.01.07 |
|---|---|
| ERD (Entity Relationship Diagram) 기초 (0) | 2022.01.07 |
| 데이터 모델링의 이해 (0) | 2022.01.07 |
| ELK) Logstash 기본 개념 (0) | 2021.12.27 |
| ELK) Elasticsearch 기본 개념 (0) | 2021.12.27 |

