프로젝트 개요
- 한국정보과학회
- 가상화 환경에서의 NUMA 기반 락 성능 분석
- 2020.05~2020.0
- 고성능 컴퓨팅
이전 글 에서 작성했던 논문으로 한국정보과학회 저널 투고 요청을 받아 [가상화 환경에서의 NUMA 기반 락 성능 분석] 에서 실험을 추가하고 보완한 논문입니다.
한국정보과학회
한국정보과학회
www.kiise.or.kr
가상화 환경에서의 NUMA 기반 락 성능 분석
Performance Analysis of NUMA-aware Locks in Virtualized Systems
최근 CPU 및 메모리 측면의 확장성을 위해 데이터 센터 및 클라우드 플랫폼에서는 NUMA 기반의 서버를 많이 활용하고 있다. 이에 따라 시스템의 성능 최적화를 위해 호스트 시스템에서는 NUMA 구조의 특징을 활용한 연구가 많이 수행되었다. 가상화 시스템 역시 NUMA 기반 시스템에서의 성능 최적화를 위해 가상 NUMA(vNUMA) 기능을 각 가상 인스턴스에 제공하고 있으며, 이를 통해 게스트 운영체제가 NUMA 관련 최적화 기법을 활용할 수 있도록 하고 있다. 하지만, 대부분의 NUMA 관련 최적화 연구는 호스트 환경에서 수행되었기 때문에 여러 가상머신이 하드웨어 자원을 공유하는 환경에서는 NUMA 최적화 기법들의 성능 이점이 크게 줄어 들 수 있다. 본 논문에서는 vNUMA를 활용하는 단일 및 다중 가상머신 환경에서 NUMA 기반 락 기법을 커널 영역 및 유저 영역에 적용한 다음 성능을 측정하고 분석하였다. 실험 결과, 단일 가상머신 환경에서 NUMA 기반 락 기법의 성능이 호스트와 유사하게 나타나지만, 다중 가상 머신 환경에서는 LWP 문제로 인해 NUMA 기반 락 기법의 성능 이점이 크게 감소하는 것을 확인하였다.
Recently, NUMA-based servers have been utilized in the data centers and cloud platforms for the scalability in the aspects of CPU and memory resources. Accordingly many studies were conducted in the native system to optimize system performance using the characteristics of NUMA architecture. Virtualized system also provide virtual NUMA(vNUMA ) to each virtual machine for allowing guest operating systems utilize NUMA-related optimization technique. Unfortunately, since most NUMA-related optimization studies have been conducted in the native system, the performance benefits of these techniques can be significantly reduced in environments where multiple virtual machines(VMs) share hardware resources. In this paper, we analyze the performance of NUMA-aware lock, which is applied to the kernelspace lock and userspace lock, on the vNUMA-based single and multi VM environments. Experimental results show that, in a single VM environment, the performance of NUMA-aware lock is similar to that of the host, whereas in multiple virtual machine environments, the performance benefits of NUMA-aware lock have been significantly reduced due to LWP problems.
키워드 : NUMA구조, 락, 가상머신, vCPU 선점
-
추가 실험 방법 및 결과
KCC2020 논문 추가 실험
VM 기본 조작 명령
www.notion.so
-
MCS 락 vs CNA 락

-
MCS 락
MCS락은 멀티 코어 환경에서 많이 쓰이는 락으로 락을 대기하는 쓰레드에게 개별적인 큐 노드를 제공한다. 기존 스핀락과 달리 락을 얻기 위해 대기하는 쓰레드들은 각자의 큐 노드 내부에서 루프를 돌기 때문에 캐시 라인 바운싱 문제를 해결할 수 있으며, 이로 인해 다중 쓰레드 환경에서 최적화된 성능을 보장한다. 또한, FIFO 방식으로 락의 소유권을 전달하기 때문에 락 획득에 대한 공평성을 보장한다. 하지만 MCS락은 NUMA 시스템을 고려하지 않았기 때문에 NUMA 환경에서는 최적화된 성능을 보장하지 못한다.
-
CNA 락
CNA락은 NUMA 구조를 고려하여 두 개의 큐 구조를 활용한다. 메인 큐에서는 락을 소유한 쓰레드와 같은 소켓에 있는 락 대기 쓰레드를 정렬하고, 보조 큐에서는 외부 소켓에 있는 락 대기 쓰레드를 정렬한다. 쓰레드가 락을 얻으려고 하면 항상 메인 큐에 먼저 합류하지만, 만약 락을 소유한 쓰레드가 해당 쓰레드와 다른 소켓에 있다면 보조 큐로 옮겨진다. 그리고 현재 락을 소유한 쓰레드는 락을 풀려고 할 때, 메인 큐를 순회하며 락 소유권을 넘길 쓰레드를 찾는다. 이러한 방식으로 로컬 쓰레드에게 락 획득에 대한 우선권을 부여한다. 그리고 주기적으로 보조 큐의 쓰레드들을 메인 큐로 옮겨 외부 소켓에 락에 대한 소유권을 주기도 하는데 이는 다른 소켓에 있는 쓰레드의 락 기아 상태를 방지하고 롱텀 공평성을 보장하기 위함이다.
추가 실험 결과
-
호스트에서의 Stock락과 CNA락의 MWRL 워크로드 성능

호스트 환경에서 NUMA 기반 락으로 인한 성능 이점을 확인하기 위해 FxMark 벤치마크의 MWRL워크로드를 이용해 성능을 측정하였다. 리눅스의 기본 락의 경우 쓰레드의 수가 단일 소켓의 코어 수인 16개가 될 때까지는 성능이 지속적으로 증가하지만 단일 소켓의 코어 수를 넘어서면 성능이 최대 49.6%까지 감소한다. 반면, CNA 락은 쓰레드의 수가 증가하더라도 성능의 감소 폭이 초대 12.4%로 비교적 작게 나타나며, 쓰레드의 수가 64개인 경우에는 Stock에 비해 성능이 약 1.87배 정도 높은 것을 확인할 수 있다.
-
커널 영역에서의 NUMA 기반 락 성능 분석
-
FxMark의 MWRL 워크로드
MWRL 워크로드는 개별 파일에 대해 rename 연산을 수행하는 워크로드로 쓰기 락을 획득하기 위한 대기 시간이 실행 시간의 대부분을 차지하는 특징을 가진다.
-
단일 가상머신 환경에서의 Stock 락과 CNA락의 MWRL 워크로드 성능
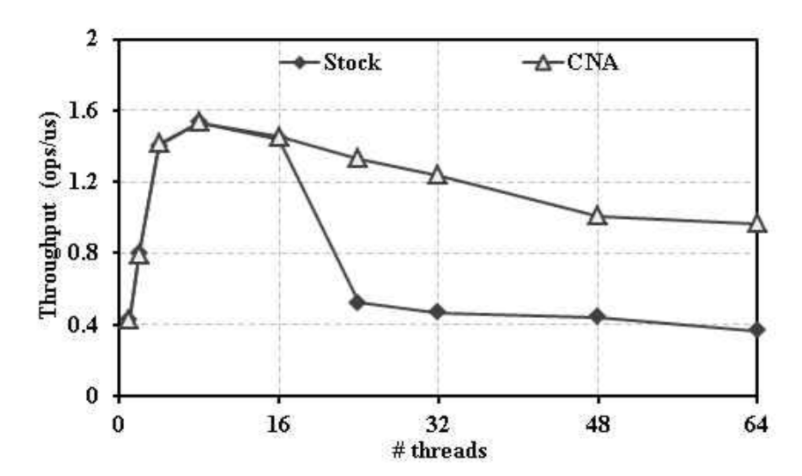
단일 가상머신 환경에서는 호스트와 마찬가지로 쓰레드의 수가 단일 소켓의 코어 수인 16개에 도달할 때 까지는 두 개의 락 모두 성능이 증가하며, 이후 Stock의 경우에는 성능이 최대 76.1%까지 가파르게 감소하는 양상을 보인다. 반면, CNA 락은 쓰레드의 수가 16개 보다 많은 경우에 도 약 36.9% 정도의 성능 감소만을 보인다. 이러한 실험 결과를 통해 단일 가상머신 환경에서는 NUMA 기반 락 최적화 기법이 호스트와 유사하게 동작하는 것을 알 수 있다.
-
다중 가상머신 환경에서의 Stock 락과 CNA락의 MWRL 워크로드 성능
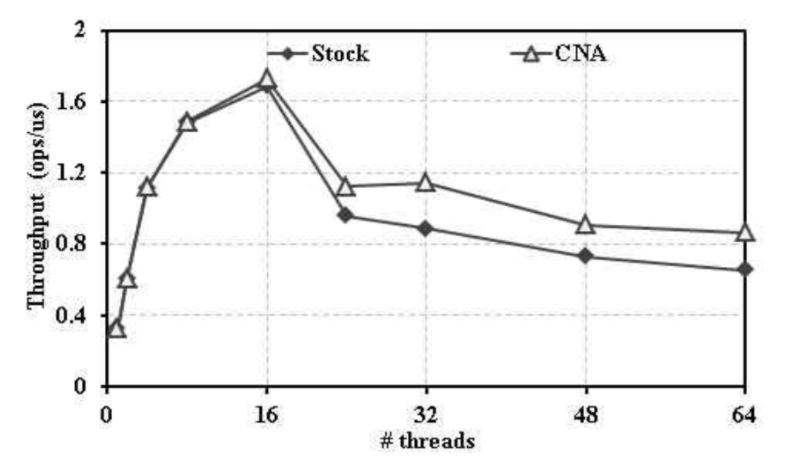
Stock과 CNA 락 모두 쓰레드의 수가 단일 소켓의 코어 개수인 16개에 도달할 때까지는 성능이 증가하지만 이후, Stock 은 61.1%, CNA 락은 49.9% 정도의 성능 감소를 보인다. 특히 CNA 락의 경우에는 단일 가상머신 환경에서 실험한 결과와 비교했을 때, 멀티 소켓에서의 성능 감소 폭이 더 크게 나타나며, Stock과의 성능 차이 또한 줄어들었다. 다중 가상머신 환경에서 성능이 감소하는 이유는 CNA 락의 메인 큐 내부에 같은 소켓에서 실행되고 있는 쓰레드들의 vCPU가 선점당함으로써 LWP 문제가 발생하고, 이로 인해 NUMA 기반의 최적화 기법의 성능 이점이 크게 줄어들기 때문이다.
-
유저 영역에서의 NUMA 기반 락 성능 분석
-
LevelDB의 readrandom 워크로드
readrandom 워크로드는 데이터를 읽으면서 글로벌 데이터베이스 락에 경쟁을 발생시키는 특징을 가진다.
-
단일 가상머신 환경에서의 LevelDB readrandom 워크로드 성능
쓰레드의 수가 소켓의 코어 개수를 넘어가면서부터 MCS 락과 CNA 락 모두 성능이 감소하는 것을 볼 수 있다. 하지만, CNA 락이 MCS 락에 비해 감소 폭이 덜하고 쓰레드 수가 증가할수록 그 감소 폭의 차이가 커진다. 특히 쓰레드의 수가 64개인 경우 CNA 락이 MCS 락에 비해 약 68.2% 정도 높은 성능을 보인다. MCS 락은 쓰레드 별로 큐 노드를 분리해서 관리하기 때문에 기본 스핀락에 비해서는 높은 성능을 보인다. 이를 통해 vNUMA를 적용한 단일 가상머신 환경에서는 CNA 락의 NUMA 최적화 기법이 잘 동작하며, 이로 인해 스핀락과 MCS 락에 비해 좋은 성능을 보이는 것을 알 수 있다.
-
다중 가상머신 환경에서의 LevelDB readrandom 워크로드 성능
MCS 락과 CNA 락 모두 쓰레드 수가 증가할수록 급격하게 성능이 감소하며 거의 똑같은 성능을 보인다는 것을 알 수 있다. 이는 LHP 문제와 더불어 FIFO 특징으로 인한 LWP 문제가 성능에 많은 영향을 미치기 때문이다. 반면, 기본 스핀락은 락 획득에 대한 공평성을 지켜주기 않기 때문에 LWP 문제가 상대적으로 작게 나타나며, 이로 인해 MCS 락 및 CNA 락에 비해 높은 성능을 보인다. 이 결과를 통해 다중 가상머신 환경에서 NUMA 기반의 최적화 락을 도입하기 위해서는 LHP 및 LWP 문제가 같이고려되어야 함을 알 수 있다.
원문 보기
프로젝트 리뷰
-
배운점
추가 실험을 하며 이전에 사용했던 MWRL 워크로드 이외에 levelDB readrandom 워크로드를 사용해볼 수 있었습니다. 또한 64코어 환경에서 실험을 수행하며 보다 정확한 실험 결과를 얻을 수 있었습니다. 또한 갑작스러운 저널 투고 요청으로 KCC2020에 작성했던 논문을 보완하면서 영문 교정, 심사답변서 작성 등의 다양한 논문 프로세스를 경험했습니다.
-
보완할 점
벤치마크를 세팅하는 과정에서 많은 어려움을 겪어 멘토님의 도움을 정말 많이 받았습니다 ㅠㅠ 한번 해봤으니 다음 번에는 조금 더 잘할 수 있을 거라 생각합니다 ㅎㅎ
긴 글 읽어주셔서 감사합니다 :)
'프로젝트' 카테고리의 다른 글
| [데이터 관리 프로그램/Python] What's in my Refrigerator : 냉장고 속 식재료 데이터 관리 프로그램 (0) | 2021.04.09 |
|---|---|
| [KSC2020] 소켓 간 락 전달 비율에 따른 NUMA 기반 락 성능 분석 (0) | 2021.01.29 |
| [KCC2020] 가상화 환경에서의 NUMA 기반 락 성능 분석 (0) | 2021.01.29 |
| [성균융합원 R 코딩캠프] TwitchR (0) | 2021.01.22 |
| [개방형 클라우드 플랫폼 PaaS-TA기반 서비스 아이디어 공모전] 누리자 복지 (0) | 2021.01.22 |



