Chapter4) Network Layer 네트워크 계층
processing (2021.04.20~)
1. Introduction

- 전송 계층은 logical connection을 하고 있는 것으로 양 단 사이의 디바이스들은 이 연결을 몰라도 된다.
- 네트워크 계층은 논리적 연결이 아니라 물리적 연결이 필요하다
1.1 네트워크 계층에서 제공하는 서비스
1.1.1 패킷화 packetizing
송신측에서 캡슐화, 수신측에서 디캡슐화
- 송신측에서 네트워크 계층 패킷에 있는 페이로드 (상위 계층에서 받은 데이터)를 캡슐화
- 페이로드가 너무 크면 쪼갤 필요가 있음
- 수신측에서 네트워크 계층 패킷의 페이로드를 de-capsulating
1.1.2 라우팅 routing **
- LAN과 WAN 의 조합으로 물리적 계층이 구성되기 때문에 송신-수신 간 여러 경로가 있음
- 여기서 가장 최선의 경로를 찾아주는 서비스
1.1.3 포워딩 forwading
- 라우터의 인풋을 적절한 아웃풋으로 패킷을 이동시키는 것
- 포워딩 테이블을 이용 (포워딩 밸류 - 아웃풋 인터페이스 맵핑)

1.1.4 오류 제어
- 네트워크 계층의 패킷은 각 라우터로 쪼개질 수 있기 때문에 오류 체크가 중복이 되어 비효율적일 수 있음
- 그러나 checksum field가 헤더에 추가되어 corruption을 알려줌
- 즉, 네트워크 계층에서는 checksum 이외의 별도의 오류 제어 없음
1.1.5 흐름 제어
- 상위 계층 프로토콜에서 제공하고 네트워크 계층에서는 제공하지 않는 서비스
- 상위 계층이 데이터 수신을 위해 버퍼를 사용
- 흐름 제어는 네트워크 계층을 복잡하고 비효율적으로 만들 수 있기 때문에 제공 X
- 네트워크 계층의 주요 목적은 routing!! 그래서 오류 및 흐름 제어는 상위 계층에서 서비스 하고 여기서는 하지 않음
1.1.6 혼잡 제어
- 인터넷 네트워크 계층에서 제공 X
1.1.7 more
- 상위 계층에서 적절한 규칙, 조항 들을 구현해서 서비스 질 높임
- 네트워크 계층에서는 보안에 관한 규정이 명시 X
1.2 Packet Switching
- 기법
- circuit switching
- packet swtiching : 전송 계층에서 메시지들을 적절한 크기의 패킷으로 쪼개고 네트워크를 통해 각 패킷을 전송
- 접근법 1: datagram approach - 비연결 서비스
- 접근법 2: virtual circuit approach (가상 회선) - 연결 지향 서비스
1.2.1 packet switching - datagram approach
- connectionless 서비스
- 각 패킷 간 관계 없음
- 각 패킷은 헤더에 담긴 정보를 기반 -> 포워딩 테이블을 사용해서 라우팅
1.2.2 packet switching - virtual circuit approach
- connection oriented 서비스
- 데이터그램을 보내기 전에 경로를 지정해두는 가상 연결
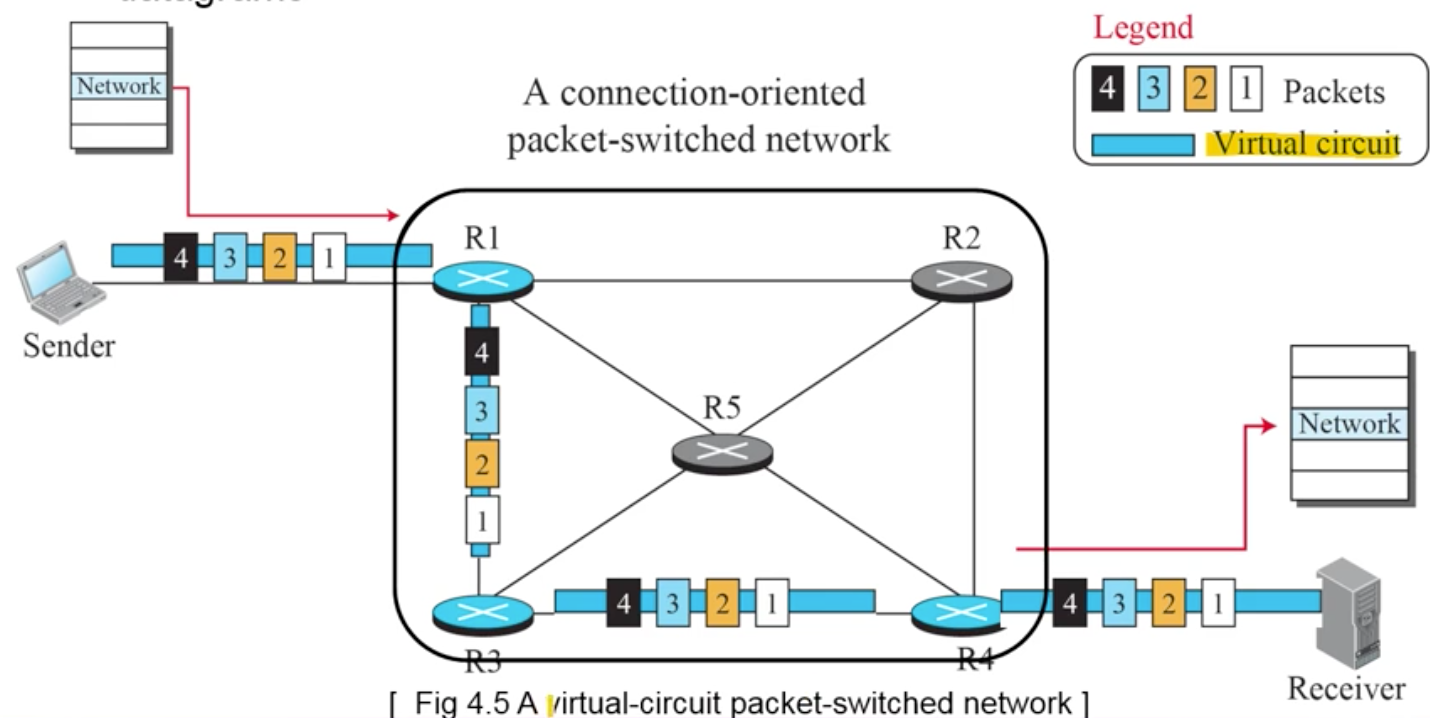
- 각 패킷들은 패킷에 담겨 있는 라벨을 기반으로 라우팅

- set-up 단계
- request 패킷과 acknowledge 패킷은 교환되어야 함 (송수신간 패킷 교환)
- 일단 request 패킷을 가상 회선 네트워크를 통해 보냄
- 그리고 나서 ack를 패킷 라벨을 기반으로 전송
- data-transfer 단계
1.3 네트워크 계층 performance
- 성능 지표 : delay, throughput, packet loss
1.3.1 delay
- 전송 지연 시간 = packet length/transmission rate
- 전파 지연 시간 = distance / propagation speed = bit 가 한 노드에서 다른 노드로의 이동하는 시간
- 프로세싱 지연 시간 = 패킷이 라우터나 목적지에서 처리되는데 필요한 시간
- 큐잉 지연 시간 = 큐의 입 출력을 위해 패킷이 기다리는 시간
- total delay

1.3.2 throughput
- transmission rate (초당 전송되는 bit의 수)

- 전체 스루풋은 병목현상을 고려하여 TR중 최소인 것으로
- 예시에서는 throughput = 100Kbps
1.3.3 packet loss
- 라우터가 한 패킷을 처리하는 동안 다른 패킷을 받으면 그 패킷은 input 버퍼에 저장되어야 함
- 버퍼 사이즈는 제한적임
- 버퍼 풀이 되면 다음 패킷은 손실됨
- 패킷이 손실되면 네트워크계층은 그 패킷을 재전송해야 함 -> 오버플로우, 더 많은 패킷 손실 유발
1.4 Congestion

- delay는 로드가 늘어날 수록 계속해서 증가
- capa까지 스루풋이 늘다가 capa를 지나면 줄어듦 , 줄어드는 구간이 혼잡 영역
1.4.1 혼잡 제어
- open loop congestion control : 혼잡 발생 전 예방하기
- retransmission 정책 : 재전송은 피할 수 없고 이는 혼잡 제어를 유발할 수 있음 그러나 좋은 정책으로 잘 조절해야 함
- window 정책 : 윈도우를 사용하는 것
- acknowledgement 정책 : 수신측에서 발생할 수 있는 혼잡으로 모든 패킷마다 ack를 받지 않으면 보내는 쪽에서 혼잡을 예방하고자 보내는 속도를 늦출 수 있음
- discard 정책 : 라우터에서 수행할 수 있는 정책으로 전송의 무결성을 해하지 않기 위한 혼잡 제어 방식
- admission 정책 : 양질의 매커니즘을 제공하기 위한 정책
- closed loop congestion control : 혼잡 발생 이후 이를 완화하기 위한 방식
- backpressure
- choke packet
- implicit signaling : source가 혼잡이 발생한 노드와 직접 소통하지 않고 추측
- explicit signaling : ATM 네트워크에서 사용한 것으로 양 방향으로 명시적 시그널 보냄 -> chapt.5
1.5 Practice problem (1)


1.6 라우터의 구조
1.6.1 컴포넌트

- input port

- output port

- routing processor
- 네트워크 계층의 주요 기능
- 다음 hop의 주소를 찾으면서 도잇에 패킷을 보냇 output port를 찾음
- switching fabric
- banyan ex) input 1, output 6(110)으로 보내는 거면 1 bits에서 1 -> (A-2) -> (1) -> (B-4) -> (1) -> (C-4) -> (0) -> 6
- 조합해서 쓰면 충돌 줄어듦

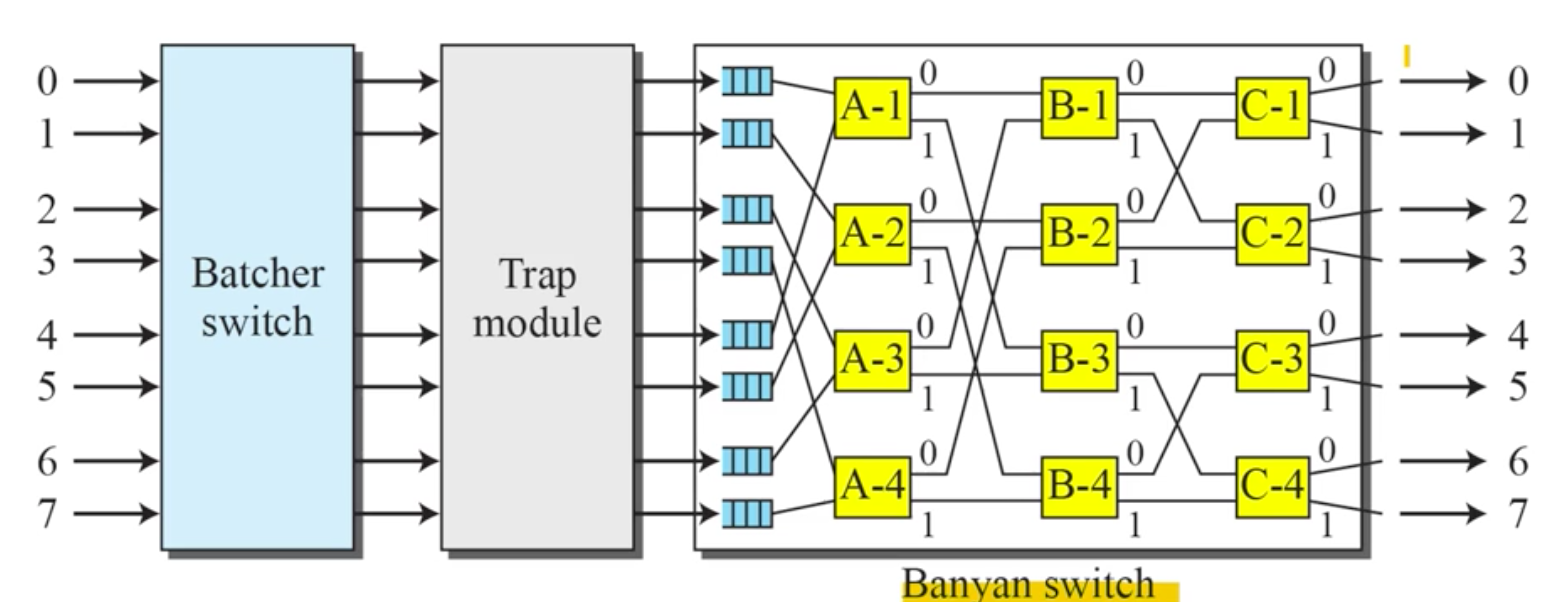
2. Network-Layer Protocols

2.1 TCP/IP 프로토콜의 네트워크 계층

2.1.1 IP Datagram 포맷

- VER (version) : IP프로토콜의 버전을 나타내는 4 bit (4 -> 6으로 대체되는 중)
- HLEN (header length) : 데이터 그램 헤더의 전체 길이(4 byte words) 로 4 bit, 헤더 길이 다양하기 때문에 필요한 필드
- service type : 서비스 타입을 나타내는 8 bit 필드
- total length : 16bits 로 IP 데이터그램의 전체 길이 바이트를 나타냄 (데이터 길이 = 전체 길이 - 헤더 길이)
- identification : 단편화를 위해 사용하는 16 비트
- flag: 3 bits
- time to live : 타임스탬프를 위해 사용되는 필드였으며 각 방문된 라우터에 의해 감소되는 필드, 데이터그램이 인터넷을 돌아다니며 살아갈 수 있는 시간으로 0이되면 라우터는 이 데이터그램을 버린다. 데이터그램이 방문할 수 있는 hop의 개수 제한
- protocol : 8 bit / IP 계층에서 사용하는 서비스를 정의
- checksum : 16 비트, 에러 체크를 위해 사용
- source address : 32 bits 필드로 송신지의 ip 주소 정의
- destination address : 32 bits 필드로 수신지의 ip 주소 정의
- max transfer unit : 데이터그램을 프레임에 캡슐화할 때 데이터그램의 전체 사이즈는 MTU보다 작아야 함
- fragementation 관련 필드 : 단편화된 조각은 데이터그램을 쪼갠 조각으로 네트워크를 통과할 수 있음, 각 단편화조각은 각자의 해더를 가지고 있으며 수신측 에서 다시 재조립
- identification: source host에서 기원한 데이터 그램을 식별하는 16 비트 필드, 수신측에서 재조립하기 위해 사용
- flags : 3bit (reserved - do not fragment bit - more fragment bit)
- fragmentation offset (13 bits) : 8 바이트의 단위/ 원래 데이터그램에서 사용되는 오프셋

2.2 Practice problem

2.3 Security of IPv4
- packet sniffing
- packet modification
- IP spoofing
- IP sec
- 알고리즘과 키 정의하기
- 패킷 암호화
- 데이터 무결성
- 원본 진위성


2.4 IPv4 주소
- IP 주소 : 32 비트, 고유하다
- IPv4의 주소 공간 = 2^32 / 4/ 294/967/296
- 표기법
- 바이너리 표기법 : IP주소가 32 비트로 표현됨
- dotted-decinal 표기법

- IPv4 주소의 계층 구조
- 두 계층이 존재
- prefix -> 네트워크 정의 / n bits
- suffix -> 노드 연결 정의 / 32-n bits
- classful addressing

- address depletion 주소 고갈
- 완화하기 위한 방식 등장
- subnetting
- 클래스 a와 b를 여러 서브넷으로 분리하고, 각 서브넷들은 일반 네트워크보다 아주 큰 prefix 길이를 갖게 한다. 즉, 큰 블럭을 작은 블럭들로 쪼깨는 것
- not working
- supernetting
- 여러개의 C 클래스 블럭들을 큰 블럭으로 조합하여 많은 IP가 필요한 기업이 제공
- not working
- classless addressing (21분 참고)
- 네트워크를 정의하는 prefix가 작다는 것은 네트워크 내부의 노드들이 많아서 그 길이가 길다는 것이기 때문에 네크워크가 크다는 것을 의미한다.
- 블럭의 주소 개수는 반드시 2의 제곱
- 첫번째 주소는 반드시 주소의 개수로 나누어 떨어짐
- 주소는 반드시 mask가 동반되어야 함
- mask - prefix : 주소 범우의 공통적인 부분으로 classful addressing에서 네트워크를 나타내는 것과 유사한 역할 / /n - n이 prefix 길이 /
- mask - suffix : hostid와 비슷 / 32-network bit in CIDR 표기
- /n -> 앞에서부터 n만큼 네트워크 아이디로 공통 부분이고 그 뒤에 남은 suffix가 다름
- 아래 예시에서 첫번째 주소를 보면 27까지는 모두 같고 그 뒤에 5개의 이진수만 다름 첫번째는 00000 마지막은 11111 근데 나열한 이진수를 계산해보면 첫번째 주소는 01000000 = 64, 마지막 주소는 01011111 = 95



- 네트워크 주소계산예시
- 주소 블럭에서 첫번째 주소 (네트워크 주소) 는 네트워크에서 패킷 라우팅을 하는데 중요함
- ex1 ) 1000개 주소를 요구, 1000은 2의 멱승 중 가장 가까운 값이 1024 => prefix 길이 n = 32-log1024 = 22 , 따라서 사용 가능한 블럭은 18.14.12.0/22
- ex2 ) 14.24.74.0/24 가 시작 주소 => 블럭에 주소 2^(32-24) = 256 개 주소 14.24.74.0/24~14.24.72.255/24
- ex3 ) 120개의 주소가 필요한 경우 => 128 (2^7) 주소 할당 (요구하는 것보다 큰 것중 가장 작은 2의 n승) => 32-7 = 25 => /25
- ex4 ) 10개 주소 필요한 경우 => 16개 할당해줘야 함 => 32-16 = 28 => /28 => 첫번째 주소 ...192/28 -> 마지막 주소 ...207/28
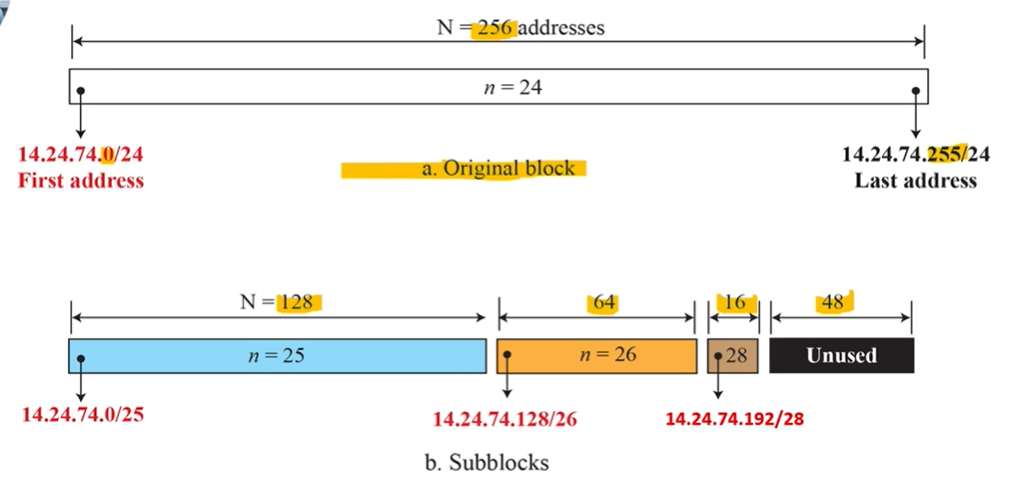
- CIDR 전략 -> 주소 군집을 만드는 장점
- special addresses
- This-host : 0.0.0.0/32 => 보내는 쪽이 자신의 주소를 모르는데 IP 데이터그램을 보내는 경우
- Limited-broadcasr : 255.255.255.255/32 => 라우터가 모든 디바이스에 데이터를 보내는 경우
- Loopback : 127.0.0.0/8 => 항상 목적지로만 사용되는 주소
- private : 10.0.0.0/8 , 172.16.0.0/12 . 192.168.0.0/16 , 169.254.0.0/16
- multicast : 244.0.0.0/4 => 멀티캐스트 주소로 예약된 것 => 11100...

2.5 IPv4 : DHCP
- dynamic host configuration protocol
- 네트워크에 새로운 호스트가 들어오면 그 때 주소를 정해주는 동적인 방식
- ICANN에서 ISP를 받아서 나눠쓰는 방식 => DHCP
- 영구적 / 임시로 호스트에 할당하는 IP 주소
- 메시지 포맷

- 네트워크에 조인하는 호스트가 DHCPDISCOVER 메시지를 만듦 -> 트랜잭션 아이디 필드가 랜덤 넘버로 설정됨
- DHCP 서버 (스위치나 라우터에 있음) 는 DHCPOFFER 메시지에 응답함 -> Your IP 주소와 서버 IP 주소가 정해짐
- 호스트가 DHCPREQUEST를 보냄
- 서버가 DHCPACK으로 응답함
- 트랜잭션 id를 식별자로 계속 들고 다님

- well-known ports : 68, 67
- 에러 제어 : UDP를 사용해서 체크섬이나 타이머, 재전송 정책 등을 사용
- 전체 로직

practice problem

2.6 IPv4 : NAT
- Network Address Translation
- 외부 - 내부 주소 분리해서 사용 하는 것
- private - universal 주소를 분리 -> 매핑

- IP 주소 + 포트 주소 모두 사용
2.7 Forwarding IP packets
- Next-Hop method : 다음 hop 주소만을 가진 라우팅 테이블
- Network-specific method : 목적지 네트워크 주소를 정의하는 하나의 엔트리만 가짐

- Host-specific method : 라우팅 테이블에 목적지 호스트 주소만을 저장해둠 , 효율성 떨어짐

- default method: 정의된 next hop이 없을 때 디폴트로 가는 곳 지정
- based on label
- 연결 지향 네트워크에서 스위치틑 패킷에 붙어있는 라벨을 기반으로 패킷을 보냄
- switching table 존재
- MPLS (Multi Protocol Label Switching) : 라우터처럼 동작할 때는 목적지 주소로 패킷을 보내고 스위치처럼 동작할 때는 라벨을 보고 패킷 보내는 기법
기말 >>
3. Network Layer Protocol
3.1 ICMPv4
internet control message protocol

3.1.1 IP protocol
- 에러 리포팅 매커니즘 없음
- 에러 수정 매커니즘 없음
- built in 매커니즘 없음
- IP 데이터그램 = IP 헤더 + IP 데이터
- IP 데이터 = ICMP 메시지

3.1.2 ICMP message
- 구성 요소
- error reporting : 라우터 또는 목적지 호스트마 IP 패킷을 처리하면서 마주한 문제를 보고하는 메시지
- query : 호스트나 네트워크 관리자에게 라우터나 다른 호스트로부터 정보를 전달하는 데 필요한 것

- source quench : 네트워크에 혼잡이 있어서 source 속도를 늦추라고 하는 것
- router solicitation
- 포맷
- 8바이트 헤더
- 다양한 크기의 데이터 섹션
- 에러 리포팅 메시지에 data section에 에러가 존재하는 원본 패킷을 찾는데 필요한 정보를 담고 있음
- 쿼리 메시지에 타입을 기반으로 데이터 섹션이 추가 정보를 담고 있음

- 에러 리포팅 메시지
- ICMP는 항상 original source에 대한 에러 메시지를 레포트
- ICMP 에러 메시지는 첫번째 조각이 아닌 다른 조각난 데이터그램에 대해서 생성되지 않음 즉, 첫번째 데이터그램 조각에서만 생성됨
- ICMP 에러 메시지를 가지고 있는 데이터그램에 대하여 ICMP 에러 메시지가 생성되지 않음
- ICMP 에러 메시지는 멀티캐스트 주소를 가지고 있는 데이터그램을 위해 생성되지 않음
- ICMP 에러 메시지는 127.0.0.0, 0.0.0.0과 같은 특별한 주소를 가진 데이터그램에 대해서는 생성되지 않음

3.1.3 도달할 수 없는 목적지
- 라우터가 데이터그램 경로에 도달할 수 없거나
- 호스트가 데이터그램을 전달할 수 없는 경우
- 데이터그램은 버려짐
- => destination-unreachable 메시지를 source 호스트로 돌려보냄
3.1.4 Source Quench
- ICMP에 source-quench 메시지는 IP에 대한 흐름제어의 일종으로 설계됨
- 라우터나 호스트가 혼잡으로 인해 데이터그램을 버리는 경우, 해당 데이터그램의 sender에게 source-quench 메시지를 보냄
- 가지고 있는 내용->sender에게 전달
- 해당 데이터그램이 버려졌음을 sender에게 알림
- 경로상에 혼잡이 있음을 알림
- 송신 프로세스를 느리게 해야 한다는 것을 알림
3.1.5 Time exceeded
- code 0 : 라우터가 데이터그램의 time-to-live(TTL) value을 0으로 만들면 그 데이터그램을 버리고 original source로 time-exceeded 메시지를 보냄
- code 1 : 마지막 목적지가 설정한 시간 내에 모든 fragment 들을 받지 않았다면 받은 조각들을 버리고 original source로 time-exceeded 메시지를 보냄
- traceroute 프로그램
- 패킷의 source -> destination 경로를 추적 하는데 사용
- ICMP 메시지와 IP패킷 내부의 TTL(time to live) 필드를 사용해서 경로를 찾음
3.1.6 parameter problem
- code 0
- 헤더 필드 중 하나에 에러 ambiguity가 있는 경우
- pointer 필드의 값 = 문제가 있는 바이트를 가리킴
- code 1 : 옵션의 필수적인 부분이 빠진 경우
3.1.7 Redirection
- 호스트는 점진적으로 커지고 갱신되는 라우팅 테이블을 사용
- 호스트의 라우팅 테이블을 갱신하기 위해 라우터는 호스트로 IP 패킷에 담아 리디렉션 메시지를 보냄
- code 0 : network-specific route
- code 1 : host-specific route
- code 2 : 특정 타입의 서비스를 기반으로 하는 네트워크 특정 경로 리디렉션
- code 3 : 특정 타입 서비스를 기반으로 하는 호스트 특정 경로 리디렉션
3.1.8 echo request and reply
- ping 프로그램 : 호스트가 살아있고 응답을 보내는지 확인하기 위해 사용하는 프로그램
4. Unicast routing
- 인터넷 상에서 네트워크 계층의 목표는 source -> destination 데이터 그램 전달하는 것
- 데이터그램의 목적지가 하나라면 유니캐스트 라우팅 사용 (one-to-one delivery)
4.1 Least-cost routing
- 최선의 경로를 찾기 위해 인터넷은 그래프 모델을 기반으로 함
- 노드 = 라우터
- 간선 = 각 라우터간 네트워크
- 가중치 그래프 weighted 그래프
- 최소 비용 라우팅 least cost routing = 최선의 경로라고 간주
- 인터넷 상에 N개의 라우터가 있다면, N-1 least cost 경로들이 라우터간 존재함
- 전체 인터넷을 위해서는 N(N-1)개의 least cost path 필요
- least-cost tree
- 특정 노드를 source로 잡고 다른 노드로의 연결성을 보여주는 그래프
- 특정 노드 기준 모든 다른 노드들을 방문
- 어떤 노드를 기준으로 하건 least cost tree 그릴 수 있음
4.1.1 거리-벡터 라우팅
- 두 노드 사이의 최소 비용 경로 = 최소 거리 경로 라고 간주

- Bellman-Ford 알고리즘
- 두 노드간 최단 경로 최소 비용을 찾는데 사용되는 공식
- x와 y 사이의 경로 중 최단 경로를 구하는 것

- 초기화
- 각 노드는 오직 자기 자신과 자신의 이웃 노드까지의 거리만 알고 있음
- 아래 예시에서 A는 처음에 자기 자신과의 거리 0, 이웃인 B, D까지의 거리만 알고 있음

- sharing
- 노드틑 이웃 노드의 테이블을 인지하지 못함 -> 네트워크에서는 ICMP가 호스트간 이 정보를 알려주는 것
- 각 노드의 최선의 방법은 전체 테이블을 이웃에 보내서 이웃 (호스트)이 어떤 것을 사용하고 어떤 것을 버릴건지 결정하게 두는 것 -> 반복 -> 결국 자기 자신으로 그 정보가 돌아옴
- 거리 벡터 라우팅에서 각 노드들은 자신의 이웃 노드들과 자신의 라우팅 테이블을 주기적으로, 변경이 있을 때 공유함
- updating
- example
- B는 D까지의 거리를 몰랐으나 A->D는 3 이고 자기 자신(B)는 A 까지의 거리가 2이므로 B->D는 5라고 업데이트

- two-node loop instability
- 거리백터라우팅의 문제 : 불안정함
- 솔루션
- defining infinity : 대부분 구현방법 / 각 노드간 거리를 1로 설정하고 16을 infinity로 설정
- split horizon : 각 인터페이스를 통해 테이블을 flooding 하는 것 대신, 각 노드가 오직 자신의 테이블의 일부만 보냄 / 노드 B가 자기가 받은 테이블의 마지막 라인을 제거하고 다음 노드로 보냄
- poison reverse : 무한 거리에 도달하면 이것이 돌고 돌아 처음 소스로 돌아왔음을 알리는 경고
- defining infinity : 대부분 구현방법 / 각 노드간 거리를 1로 설정하고 16을 infinity로 설정
- example

- three node loop instability

4.1.2 Link-State routing
- least cost tree와 forwarding table을 생성하기 위한 알고리즘
- link state database (LSBD)
- 각 노드들은 완전한 네트워크 지도가 필요
- 각 연결의 상태를 모두 알아야 함
- 모든 연결의 상태를 모아둔 것 = LSBD

- LSBD 생성 프로세스 = flooding
- 각 노드는 이웃 노드들에게 인사 메시지 전달 -> 각 이웃 노드들의 정보 얻음 (노드의 아이덴티티, 연결 비용)
- 이웃 노드에 대한 정보의 조합 = LSP (LS 패킷)
- LSP = 노드 id + link cost + sequence number(LSP 새로운 버전이 생서되면 증가되는 숫자)
- 각 노드는 LSP를 만들고 각 인터페이스를 통해 내보냄
- 노드가 LSP를 받으면 이미 가지고 있던 LSP의 복본과 시퀀스 넘버를 비교
- 오래된 LSP는 버리고 새로운 것을 가지고 새로운 LSP의 복본을 원래 이 패킷을 보냈던 노드 외의 다른 노드들에게 보냄
- 모든 새로운 LSP를 받고나면 각 노드들은 LSBD를 갖게 됨

- least cost tree의 formation
- LSBD를 갖고 나면 각 노드들은 전체 토폴로지에 대한 복본을 가지고 있는 것
- 최단 경로 트리가 필요
- 다익스트라 알고리즘을 사용해서 최단경로트리 생성

4.1.3 path vector routing
- least cost routing 기반이 아님
- ISP간 패킷을 라우팅하기 위해 설계된 것
- spanning tree
- source에서 모든 목적지로의 경로 = best spanning tree에 의해 결정됨
- 목적지로의 경로가 하나 이상이라면 source는 자신의 정책에 부합하는 최적의 경로 선택
- source는 동시에 여러개의 정책을 적용할 수 있음
- 일반적으로 많이 사용되는 정책 : 최소 개수의 노드를 방문하는 것이 최적의 경로라고 간주
- 모든 노드의 spanning 트리 생성 후 목적지까지 최소한의 노드만 거치는 것이 최적의 경로라고 결정
- 생성 프로세스
- 노드 시작 -> 이웃 노드로부터 얻을 수 있는 정보를 기반으로 거리 백터 생성
- 노드는 이웃 노드에 인사 메시지 보내서 정보 얻음
- 각 노드들은 초기 거리백터 생성 이후 모든 이웃노드들에게 보냄
- 각 노드들은 이웃으로부터 거리 백터를 받으면 거리 벡터 업데이트



4.1.4 practice problem
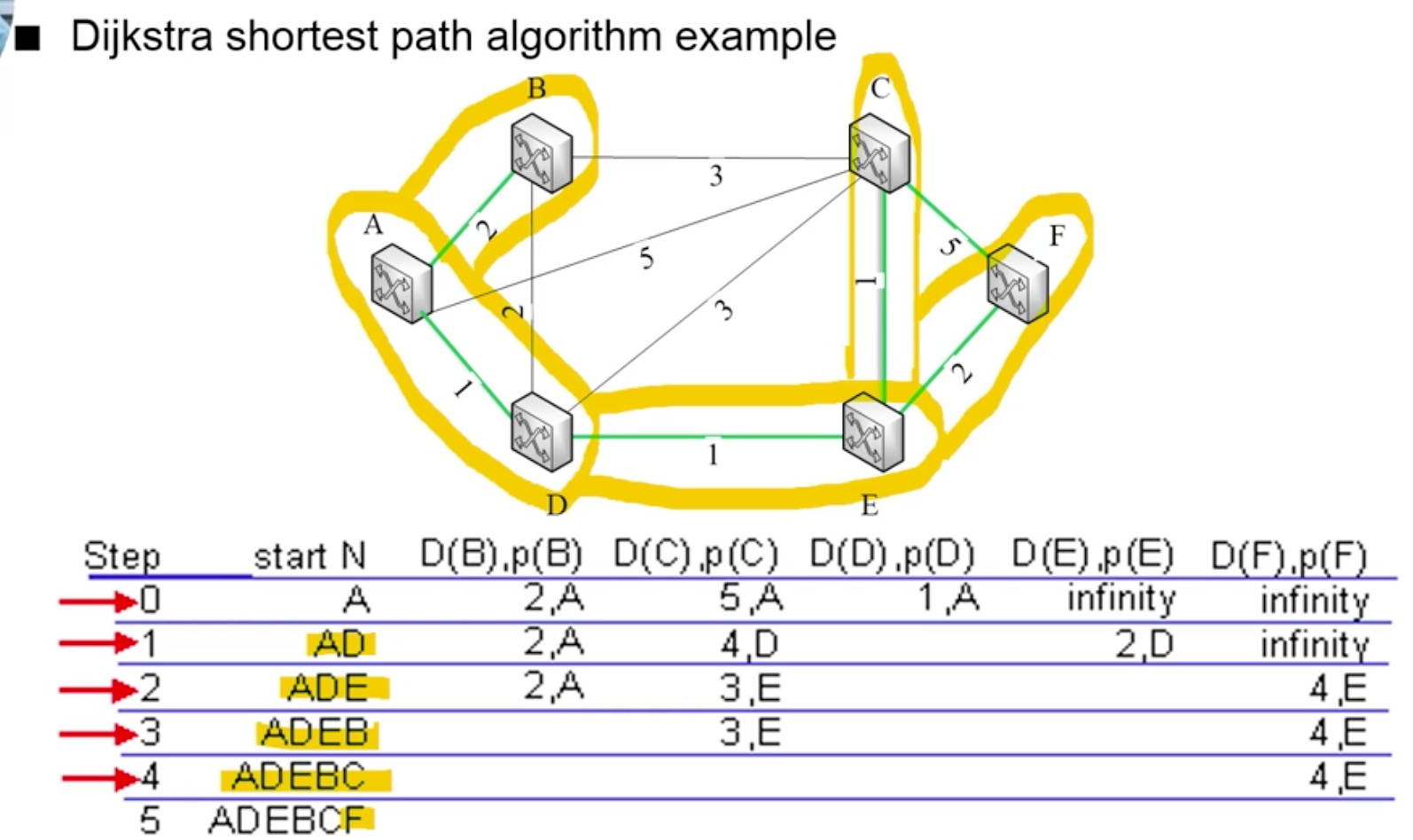
4.2 Unicast routing protocol
- 인터넷에서 사용되는 주요 프로토콜
- Routing information protocol (RIP) : 거리-벡터 알고리즘 기분
- 벨만-포드 알고리즘 기반
- open shortest path first (OSPF) : 연결-상태 알고리즘 기반
- 다익스트라 알고리즘 기반
- border gateway protocol (BGP) : 경로-벡터 알고리즘 기반
- Routing information protocol (RIP) : 거리-벡터 알고리즘 기분
4.2.1 인터넷 구조
- 백본 -> 글로벌 연결 제공
- provider 네트워크 : 낮은 수준에서 글로벌 연결을 위해 백본 사용
- custmor 네트워크 : provider 네트워크에 의해 제공되는 서비스 사용
- 위 세 객체들은 서로 다른 레벨에서 ISP(Internet Service Provider)라고 불림
- 계층적 라우팅
- 각 ISP들을 AS (Autonomous system)으로 여기는 것
- AS 내부의 라우팅 = intradomain routing
- 모든 AS들을 합친 글로벌 라우팅 = interdomain routing
4.2.2 RIP (routing information protocol)
- intradomain routing protocol
- AS 내에서 사용됨
- hop count
- 거리벡터 라우팅 기반으로 구현
- cost.= hop의 개수
- 패킷이 source -> destination 경로 상에소 패킷이 거쳐야 하는 네트워크의 개수
- RIP 에서 최대 비용 = 15 -> 16은 무한을 의미
- forwarding table

- RIP 구현
- 애플리케이션 계층에서 실행
- 포워딩 테이블은 네트워크 계층에서 생성
- UDP port 520 - 라우트 업데이트를 위해 사용
- 1, 2 버전 존재 -> 수업에서는 2만 다룸
- RIP 메시지
- request : 타임아웃 엔트리를 가진 라우터나 방금 나온 라우터가 보내는 요청 메시지
- response (or update) : 응답은 solicite/unsolicite 모두 가능,solicite는 요청에 대한 대답으로만 보내지고, unsolicite는 주기적으로 보내짐 (매 30초마다 또는 라우팅 테이블에 변화가 있을 때마다)
- RIP 알고리즘 : 거리벡터 알고리즘

4.2.3 OSPF (Open Shortest Path First)
- intradomain 라우팅 프로토콜
- 링크-상태 라우팅 프로토콜 기반
- 각 링크들은 throughput, round trip time, reliability, hop count 등을 기반으로 하는 가중치를 할당 받음
- 가중치 = cost

- 가중치 = cost
- forwarding table
- 각 OSPF 라우터
- 다익스트라 알고리즘을 사용해서 자기 자신과 목적지 사이의 shortest path tree를 찾음
- 그리고 포워딩 테이블을 생성

- Area
- OSPF는 autonomous system(AS)을 area로 나눔
- 각 area는 autonoumous system 내부에 포함된 모든 네트워크, 호스트, 라우터의 집합
- area border router : area에 대한 정보를 가지고 있고 다른 area로 보냄
- 모든 area들을 반드시 백본(backbone)이라는 특별한 arae에 연결되어 있음
- 백본과의 연결이 끊어지면 라우터는 가상 연결을 생성함

- link-state advertisement
- 라우터 링크
- 노드 = 라우터
- point to point link : 두 개의 라우터 연결
- trasient link : 여러개의 라우터들이 붙어 있는 네트워크
- stub link : 오직 하나의 라우터에 연결되어 있는 네트워크

- 네트워크 링크
- 노드 = 네트워크
- 설계된 라우터
- 네트워크는 스스로 알릴 수 없으므로 연결된 라우터 중 하나를 advertise 용으로 설계
- summary link to network
- area border router에 의해 수행되는 역할
- 즉, 백본에 연결된 area 간
- 백본에 연결된 링크들의 summary를 백본에 advertise

- summary link to AS
- AS라우터에 의해 수행
- 다른 AS에서 백본 area로 advertise

- externel link
- AS 라우터가 수행
- 하나의 네트워크 존재를 외부 AS에 알림

- 라우터 링크
- 구현
- IP 서비스를 사용하는 네트워크 계층에 구현
- IP 데이터그램이 OSPF로부터의 메시지를 싣고, 프로토콜 필드 값을 89로 설정
- 버전 1,2 있는데 대부분 구현은 버전 2사용
- OSPF 메시지
- 두개의 메시지 해더
- common header - 모든 메시지에 사용
- link state general header - 일부 메시지에 사용
- 메시지 타입
- Hello 메시지 : 라우터가 자신을 이웃에 알리기 위해 사용
- DB description 메시지 : hello 메시지에 대한 응답, 새롭게 참여한 라우터가 full LSDB 사용하는 것을 허가
- Link-state request 메시지 : 특정 링트 상태에 대한 정보를 요청하기 위해 사용
- Link state update 메시지: LSDB 설치를 위해 사용
- Link state acknowledegment 메시지 : OSPF reliability 생성을 위해 사용
- 두개의 메시지 해더
- OSPF 알고리즘
- link state 라우팅 알고리즘 구현
- 각 라우터가 shortest path tree를 생성한 후, 알고리즘은 그에 해당하는 라우팅 알고리즘을 생성하기 위해 트리 사용
- 알고리즘은 다섯 타입의 메시지를 받고 보내는 것을 처리하도록 확장 되어야 함
- vs RIP
- RIP는 각 목적지 주소에 대해 가장 가까운 라우터만 추적 > OSPF는 로컬 네트워크에 연결된 모든 DB 추적
- RIP는 메트릭 값을 계상하기 위해 hop 개수 사용 > OSPF는 shortest path first 알고리즘을 사용해서 최적 경로 선택
- RIP는 주기적인 업데이트를 보내기 위해 큰 대역폭 사용 > OSPF는 네트워크 내에서의 변화만 advertise
- RIP는 15개의 라우터까지 도달 가능 > OSPF는 hop 개수 제한 없음
- RIP는 OSPF 보다 작은 규모의 네트워크로 사용
4.2.4 BGP4 (Border Gateway Protocol Version4)
- interdomain 라우팅 프로토콜
- 인터넷에서 사용됨
- 거리-벡터 알고리즘 기반
- 각 라우터들이 인터넷 내부의 어떤 네트워크에 패킷을 라우팅할 수 있도록 external BGP4(eBGP)를 각 border router에 설치
- eBGP가 설치된 두개의 라우터는 TCP 연결을 생성
- eBGP 세션에 179 포트 넘버 사용
- circled number는 각 케이스의 보내는 라우터를 정의
- 예를들어 메시지 number 1을 라우터 R1이 보낸다면 R5에게 N1 N2 N3 N4가 R1을 통해 도달할 것임을 알림

- internal BGP (iBGP)는 모든 라우터에 설치
- TCP 서비스 사용
- 포트넘버 179
- AS 내부에 라우터 쌍들 간 세션 생성 가능
- AS 라우터는 다른 AS에 대한 정보 + 해당 AS에 대한 정보 조합
- AS 라우터는 다른 AS에 업데이트된 메시지 전달
- 이러한 방식으로 모든 네트워크 디바이스들은 AS 간 데이터를 전달할 수 있게 함
- example

4.3 Unicasting
- 하나의 source 하나의 destination
- multiple unicasting : 하나의 source에서 여러개의 패킷을 보내는 것
4.3 Multicasting
- 하나의 source, 여러개의 destination
- 하나의 source로 부터 하나의 패킷으로 시작해서 라우터에 의해 복제됨
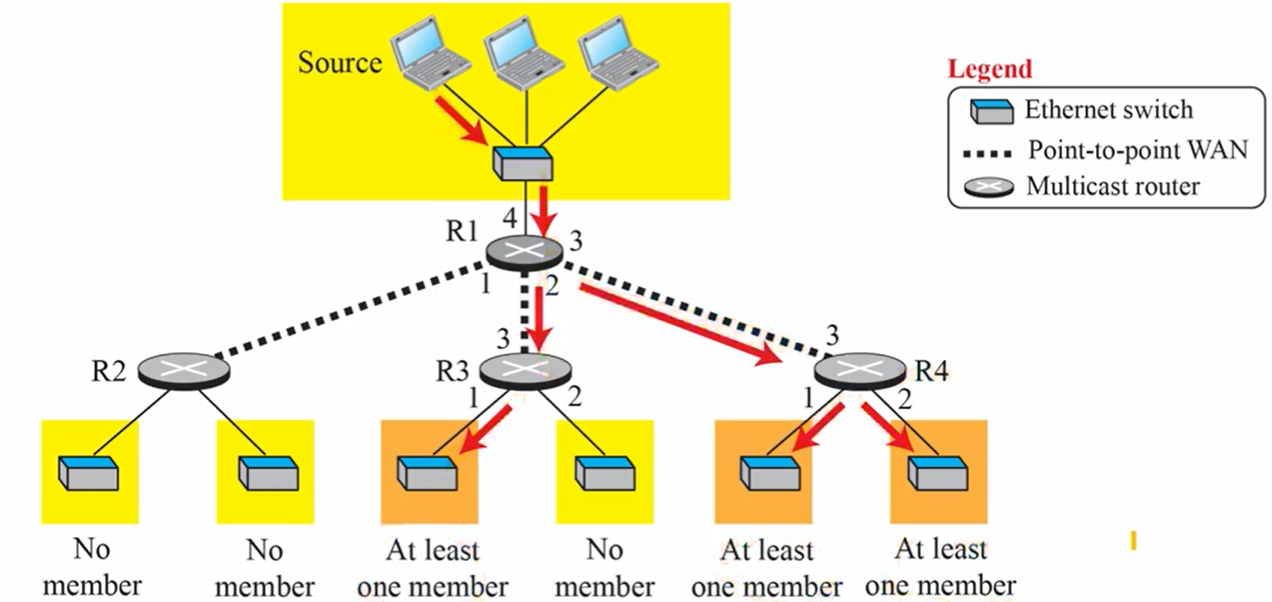
- 멀티캐스트 애플리케이션
- access to distributed DB : 사용자 요청을 모든 분산된 DB 연결로 멀티캐스트해서 정보를 가진 장소에서 응답
- information dissemination : 예를 들어 소프트웨어 업데이트가 모든 특정 소프트웨어 패키지 구매자들에게 알릴 수 있음
- teleconferencing : 동시에 같은 정보를 받아야 할 때 사용
- distance learning
4.5 Broadcasting
- one to all 소통
- 호스트가 인터넷에 있는 모든 호스트들에게 메시지를 보내는 것
4.6 Multicast 주소
- sender는 하나고 받는 쪽은 여러개 -> 멀티캐스트 주소 필요
- 멀티캐스트 주소는 받는 쪽의 그룹을 정의함
- IPv4는 주소 블럭을 할당 -> class D는 멀티캐스트 주소로 사용되는 블럭


4.7 IGMP (Internet Group Management Protocol)
- 그룹 멤버십에 대한 정보를 수집하기 위해 사용하는 프로토콜
- 네트워크 계층에서 정의
- IGMP 메시지는 IP 데이터그램에 캡슐화
- 쿼리 메시지
- 라우터가 주기적으로 연결된 모든 호스트에게 보냄
- group 내부에 멤버십 interest를 보고하도록 요청
- general 쿼리 메시지 : 아무 그룹의 멤버십에 대해 보냄, 목적지 주고 224.0.0.1로 데이터그랩에 캡슐화, 같은 네트워크에 붙은 모든 라우터들은 이 메시지를 받고 이 메시지가 도착했으며 그들은 재전송받을 필요 없음을 알려야 함
- group specific 쿼리 메시지 : 특정 그룹에 관련됨 멤버십에 대한 것만 묻기 위해 라우터로 보냄, 라우터가 특정 그룹에게 응답을 받지 못한 경우나 네트워크 내부에서 해당 그룹에 활성화 멤버가 없음을 확인하고자 할 때 보냄
- source and group specific 쿼리 메시지 : 메시지가 특정 source로부터 오면 라우터가 특정 그룹과 관련된 멤버십을 묻기 위해 보내는 메시지
- report message
- 쿼리 메시지에 대한 응답으로 호스트가 보내는 것
- 해당하는 그룹 식별자 + 모든 source 의 주소
- 멑티캐스트 주소 224.0.0.22 -> 데이터그램에 캡슐화됨
- 쿼리 메시지
References
- 성균관대학교 소프트웨어학과 추현승 교수님 2021-1 컴퓨터 네트워크 개론
'컴퓨터 공학 > 컴퓨터 네트워크' 카테고리의 다른 글
| [컴퓨터 네트워크] Application layer 애플리케이션 계층 기본 개념 정리 (0) | 2021.05.02 |
|---|---|
| [컴퓨터 네트워크] 컴퓨터 네트워크 Introduction 정리 (0) | 2021.05.02 |
| [Python3/컴퓨터 네트워크] 소켓 프로그래밍 : html request를 보내는 클라이언트와 request 받은 파일을 찾아 웹 브라우저로 보여주는 서버 프로그램 (0) | 2021.04.08 |
| [Python3/컴퓨터 네트워크] 소켓 프로그래밍 : 간단한 server-client 프로그램 만들기 (0) | 2021.04.08 |
| [Python3/컴퓨터 네트워크] 소켓 프로그래밍 : 입력한 문자열 reverse 하는 클라이언트 서버 프로그램 (0) | 2021.04.08 |